Driving by Conversation: Personalized Autonomous Driving with LLMs and VLMs

LLMs and VLMs: Enabling personalization in AVs through natural language
The evolution of autonomous vehicles (AVs) has largely focused on safety, efficiency, and technical robustness. While these remain essential, the next frontier is clear—personalization.
Today’s AV stacks typically offer static driving modes—“sport,” “comfort,” “eco”—or manual parameter adjustments. These settings are rigid, fail to capture nuanced user preferences, and cannot interpret indirect or contextual instructions. In practice, they cannot adapt when a passenger says, “I’m tired, please drive more gently,” or “I’m late, could we speed up?”
Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) open the door to natural, human-like interaction with AVs. These models can understand plain-language commands in any language or dialect, interpret subtle modifiers (“slightly faster,” “much gentler”), and integrate contextual cues from live perception data.
By combining these capabilities with the AV’s driving stack, it becomes possible to:
- Enable natural and nuanced conversation by understanding plain-language commands (in any language or dialect) and subtle modifiers (“slightly faster,” “much gentler”), replacing complex menu settings.
- Make context-aware decisions by fusing live visual cues (traffic, weather, signage) with spoken intent so the vehicle adapts safely yet personally in real time.
- Deliver personalization that improves over time via memory-augmented models recall past rides to refine each passenger’s comfort and style preferences without retraining the core stack.
The research presented here demonstrates the first end-to-end, real-world deployments of LLM- and VLM-based frameworks, Talk2Drive and an onboard VLM motion control system, integrated with a fully functional autonomous driving stack.
System Architecture: Integrating LLM/VLM with the autonomous driving stack
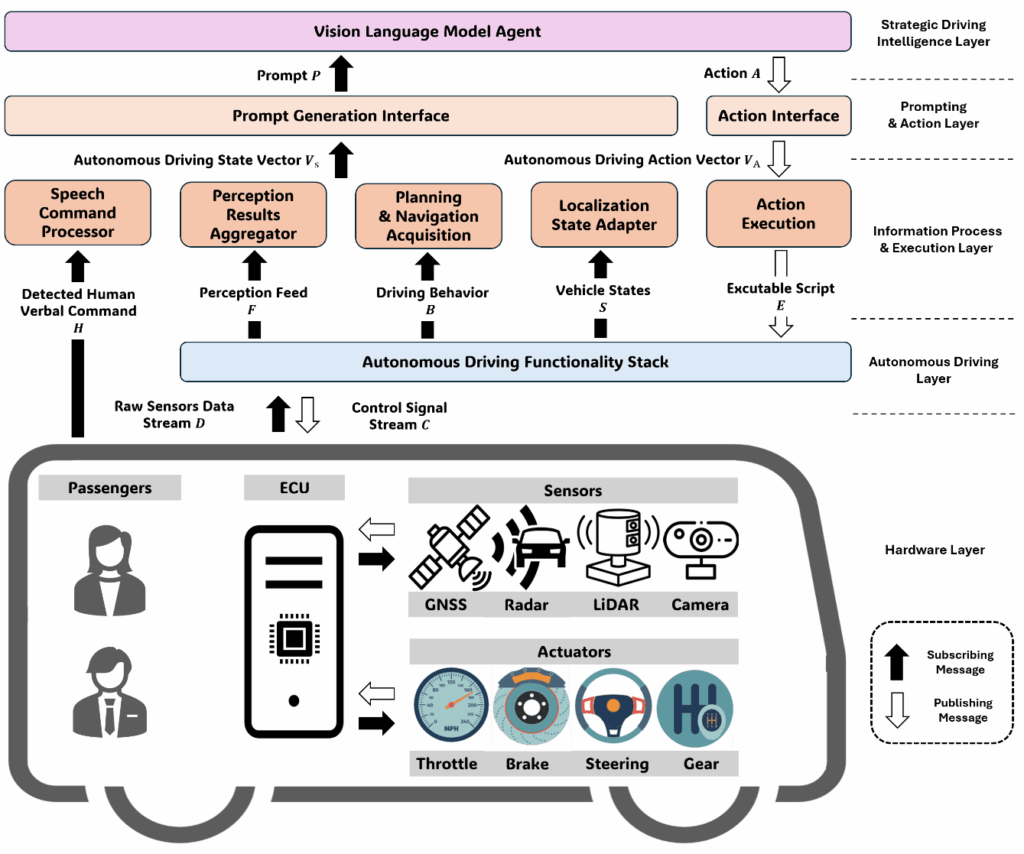
The proposed architecture embeds LLM or VLM capabilities into the Strategic Driving Intelligence Layer of the AV stack (Figure 1). It processes multimodal inputs, generates context-aware driving plans, and executes low-level controls through the existing autonomy layer.
Inputs Information:
- Human instruction (speech-to-text conversion).
- Perception results (objects, weather, traffic conditions).
- Vehicle state (pose, speed).
- Available safe behaviors (slow down, lane change, stop).
Prompt Generation Interface:
Bundles raw inputs with system context (safety rules, operational role) and historical ride data, producing a structured prompt for the LLM/VLM.
VLM/LLM Agent:
Generates high-level policy parameters, target speed, decision priorities, and control adjustments aligned with passenger preferences.
Action Interface:
Translates high-level LLM/VLM output into low-level commands executed by the autonomous driving layer.
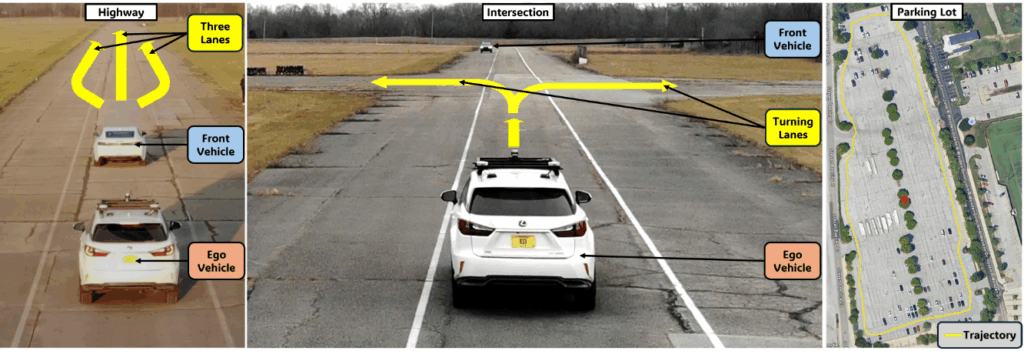
Real-World Testing Environment
To evaluate these systems, field tests were conducted at three distinct tracks:
- Highway Track – Testing lane changes, maintaining speed, responding to sudden slowdowns, and merging from on-ramps.
- Intersection Track – Handling yielding, protected and unprotected turns, and cross-traffic negotiation.
- Parking Lot Track – Navigating narrow lanes, avoiding static/dynamic obstacles, parallel parking, and reverse parking maneuvers.
These scenarios allow assessment of personalization performance across diverse traffic, speed, and maneuvering conditions.
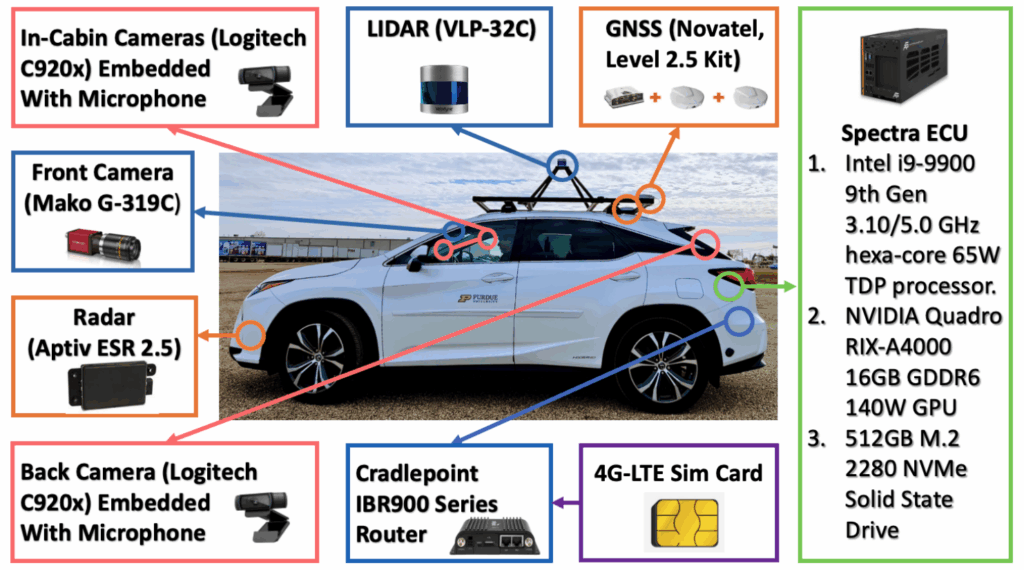
Autonomous Vehicle Hardware Setup
Experiments were conducted using a Lexus RX450h equipped with:
- Sensors: LiDAR (VLP-32C), radar (Aptiv ESR 2.5), GNSS (NovAtel Level 2.5 kit), multiple cameras (front, rear, in-cabin).
- Computing Platform: Intel i9-9900 CPU, NVIDIA Quadro RIX-A4000 GPU, 512GB NVMe SSD.
- Connectivity: Cradlepoint IBR900 Series Router with 4G-LTE.
This configuration supported both cloud-based LLM inference and fully onboard VLM inference for low-latency control.
Case Study 1: Talk2Drive: LLM-Based Personalized Driving
The Talk2Drive framework integrates GPT-4-based LLMs into a real-world AV, allowing natural verbal commands to directly influence driving behavior.
Core Capabilities:
- Understanding multiple levels of human intention – from explicit (“drive faster”) to indirect (“I’m in a hurry”) commands.
- Memory module for personalization – storing historical interaction data to refine driving style preferences over time.
Experiment Design:
- Scenarios: Highway, intersection, and parking lot.
- Evaluation metric: Takeover rate, frequency with which the human driver needed to intervene.
- Comparison: With and without the memory module.
Key Findings:
- Talk2Drive reduced takeover rates by 75.9% compared to baseline non-personalized systems.
- Adding the memory module further reduced takeover rates by up to 65.2%, demonstrating the benefit of long-term personalization.
- System successfully interpreted context and emotional tone, enabling safer and more responsive driving adaptations.
Case Study 2: Onboard VLM for Motion Control
While LLM-based systems can operate via cloud processing, they often face latency (3–4 seconds) and connectivity constraints. The second study addressed these limitations by developing a lightweight onboard VLM framework capable of real-time inference.
Key Features:
- Onboard deployment – No dependency on internet connectivity.
- Multimodal reasoning – Processing visual scene inputs and natural language instructions in real time.
- RAG-based memory module – Retrieval-Augmented Generation allows iterative refinement of control strategies through user feedback.
Experiment Design:
- Same multi-scenario real-world setup as Talk2Drive.
- Evaluated explicit and implicit commands, varying environmental conditions.
Key Findings:
- Comparable reasoning capability to cloud-based LLM solutions, with significantly lower latency.
- Takeover rate reduced by up to 76.9%.
- Maintained safety and comfort standards while adapting to individual driving styles.
Comparative Insights
| Feature | Talk2Drive (LLM) | Onboard VLM Motion Control |
| Deployment | Cloud-based (requires connectivity) | Fully onboard |
| Input Modalities | Speech/text commands | Speech/text + visual scene |
| Memory Module | Historical personalization memory | RAG-based feedback memory |
| Latency | Higher (network dependent) | Low (< real-time threshold) |
| Takeover Rate Reduction | Up to 75.9% | Up to 76.9% |
| Personalization Over Time | Yes | Yes, with continuous feedback |
Both approaches demonstrate that integrating advanced language and vision-language models with the AV stack can significantly improve personalization, trust, and user satisfaction. The choice between them depends on deployment constraints, desired input modalities, and connectivity availability.
Implications for Future Autonomous Driving
These studies represent the first real-world, end-to-end deployments of LLM and VLM personalization frameworks for autonomous vehicles. They address long-standing gaps in AV user interaction:
- Natural Command Interpretation – Understanding instructions without requiring structured input.
- Context Integration – Combining user intent with live environmental data for adaptive decision-making.
- Personalization Memory – Continuously refining the driving profile over multiple rides.
- Real-World Validation – Demonstrating effectiveness across diverse scenarios outside simulation environments.
Looking ahead, the combination of multimodal AI, onboard efficiency, and long-term personalization offers a promising path to AVs that not only drive safely but drive the way each passenger prefers.
For Further Reading:
- Personalized Autonomous Driving with Large Language Models: Field Experiments → https://arxiv.org/pdf/2312.09397
- On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control → https://arxiv.org/pdf/2411.11913


